The ability to collect large amounts of data from diverse sources—such as imaging data, electronic health records (EHR), social determinants of health data, physiological measurements like those from wearable health devices, and molecular data like next-generation genomic sequencing—has revealed untapped opportunities for transformative advancements in human health. Combining this wealth of information with novel artificial intelligence (AI) algorithms and other sophisticated analytic models increasingly makes it possible to deliver healthcare in a more precise and personalized way. The resulting paradigm, precision health, has the potential to significantly improve patient outcomes by upping diagnostic accuracy, promoting early diagnoses, tailoring therapies to individual patient circumstances, and better managing chronic conditions.
Privacy-Preserving Record Linkage
Written by Alison Amar and Erin McAuley
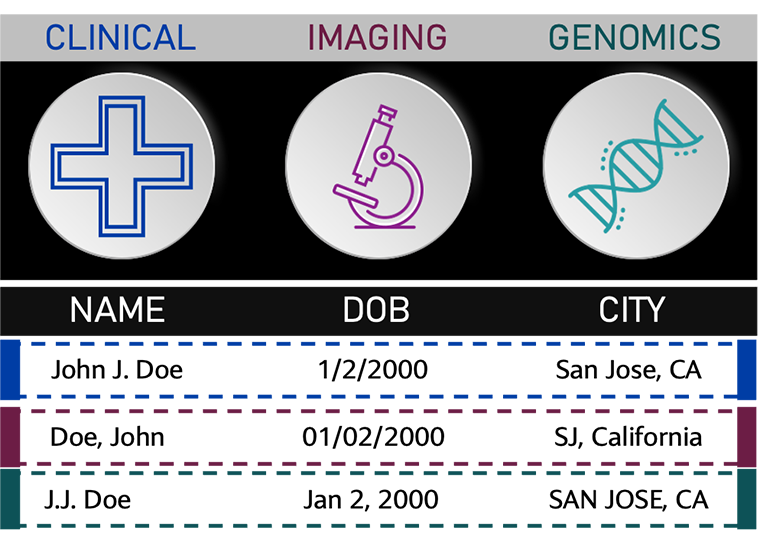 Figure 1. Example of non-standardized data to be encoded for record linkage
Figure 1. Example of non-standardized data to be encoded for record linkage