
One single individual can generate an unbelievable amount of health-relevant data.
Imagine you are surrounded by a 360-degree movie screen. Projected all around you is a digital datasphere generated by the information associated with just one individual. You see data about their past and present—where they were born, everywhere they’ve ever lived, what they eat, what schools they’ve attended, which doctors they’ve seen and why, what treatments they’ve received, what medicines and supplements they’ve taken, the impacts of those medicines and treatments, the current status of their health—everything about them up until the date, causes, and circumstances of their death.
So much data!
For health and life sciences researchers seeking to better understand human health and how to improve it, the existence of all this data raises several questions. Is it possible to access this data and to, put it all together, and make sense of it all without compromising the privacy of the person it belongs to? Can it be combined with other data in meaningful ways to help push research forward? As a picture of the past and present, can it be usefully employed to inform our thinking about the future? To help improve the health of this individual? Her family? The public at large?
Let’s repeat the above thought experiment but add privacy preserving record linkage (PPRL) to the data projected onto that 360-degree screen. Now you see a color-coded mesh of interconnected nodes spreading progressively across the digital datasphere, but all information identifying the individual this data belongs to has disappeared. As a researcher, you can now pull out the data points you need for your work—medical and family history, location and environmental history, social circumstances, and educational background—without ever knowing the identity of the person they are coming from, thus keeping their privacy intact.
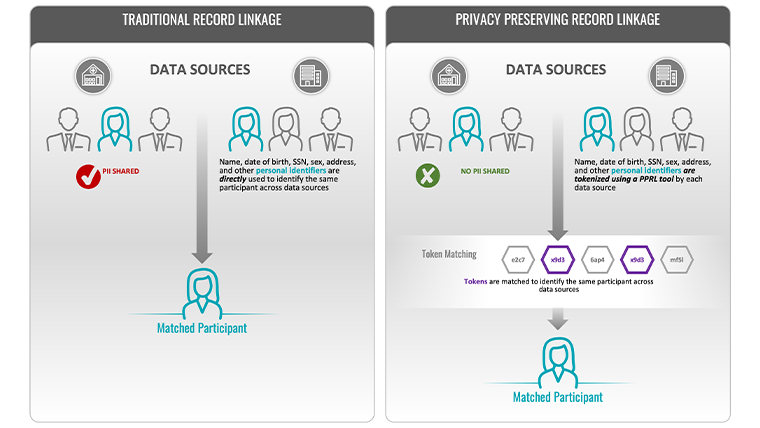 Figure 1: Traditional Record Linkage vs. Privacy-Preserving Record Linkage
Figure 1: Traditional Record Linkage vs. Privacy-Preserving Record Linkage
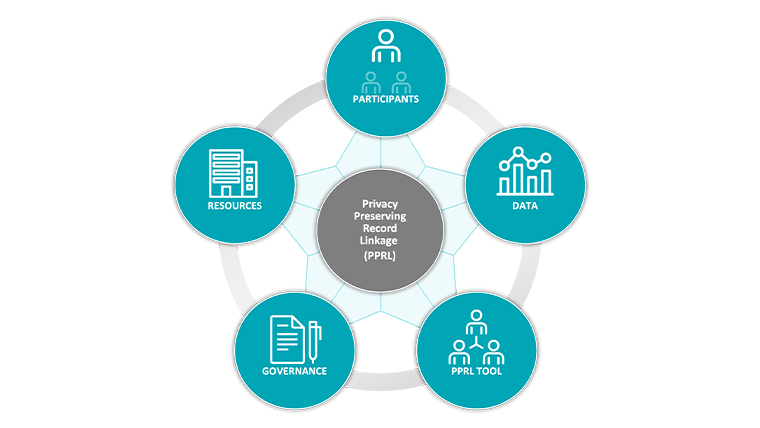 Figure 2: 5 Essential PPRL Components
Figure 2: 5 Essential PPRL Components




