
Booz Allen has decades of experience building and operating mission critical IT systems at scale. We know incidents are inevitable, and fast resolution is essential. We've lived through 3 AM server crashes and cascading failures from seemingly minor issues. When things break, engineers spend precious time piecing together clues across dozens of different systems. Even the most experienced operations team can struggle with this complexity. At Booz Allen, we're investing in Agentic AI technology that cuts through the complexity for IT operations. We developed a multiagent system that autonomously triages, validates, investigates, and provides resolution steps the moment an incident ticket is filed.
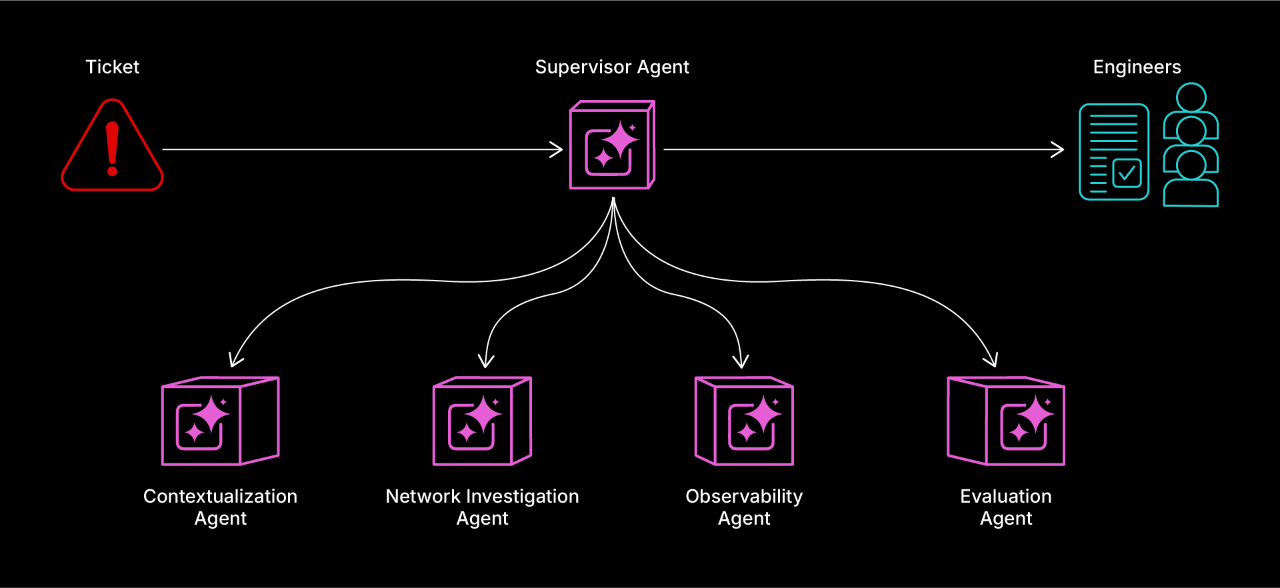
Let's take a look at an incident where an AWS node hosting an application goes down, taking down our application. What you're going to see is a multiagent system consisting of a supervisor agent and four more-specialized agents. Our supervisor is going to formulate a plan for addressing the reported failure, task the specialized agents to investigate, and ultimately create an assessment to share with the engineering team. Now, in production, all of this would occur under the hood, but we've created a front-end to observe how the agents are working. The first thing that happens is our supervisor agent sees that a ticket has been filed. It immediately formulates a plan and moves out by tasking a contextualization agent to provide more details about the issue and affected system. Our contextualization agent retrieves the requested information using a suite of tools.
The result is a contextually rich report with key information about the affected app and the issue reported. That information is handed back to our supervisor agent, which continues with its plan. The next step is to task a network investigation agent to perform a technical investigation of the affected app, beginning with network checks. The agent reaches out to our application, verifies that it's unreachable, and reports back to the supervisor. After checking network connectivity, the supervisor tasks an observability agent to investigate application logs and figure out what went wrong. As it parses the logs, the observability agent constructs a timeline of events and determines the root cause of the incident. As part of its investigation, the observability agent may access separate data stores to search for similar incidents.
If it finds one, it could leverage details of the past incident to inform its current investigation. This memory of past events means our agents can grow more intelligent over time. The supervisor agent sees this information and then invokes an evaluation agent to assess the impact of the incident and assign a priority. Finally, the supervisor summarizes all of the key findings for the engineering team and adds it all as a comment to the original ticket that kicked off the process. With Booz Allen's multiagent incident triage system, we can easily cut through system complexity and give engineers the information they need in a clear and concise format.
Our agents kick into action the moment an incident ticket hits the system, greatly accelerating response time, and with it, our mean time to resolution. It autonomously triages the issue, validates what's happening, investigates the root cause, and hands the team concrete resolution steps. Maybe the most exciting part of this is that our agents can learn. They get smarter with every incident – so engineers don't need to play detective anymore and can focus entirely on resolving issues. Users can be sure that their reported issues are getting attention immediately, and the enterprise can benefit from faster resolutions.